何玉琪老师之前有一个叫 no Free lunch,没有免费的午餐定理。说的就是各种算法在普遍意义上它没有优劣之分的。实际上一个算法好,那是因为跟他问题的结构匹配的好,而Alpha Go能做得好,是因为它正好找到了匹配围棋这样的一个结构。
工业的基础
工业的历史实际上比数据科学要早得多。
所有物理学的大厦,后来化学、生物这些科学都是构建在这些科学定律的基础上,然后整个科学大厦,又构成了我们现代工业的基础。所有的机器,生产过程,产品,都是基于物理、生物、化学的这些定律所构建的。
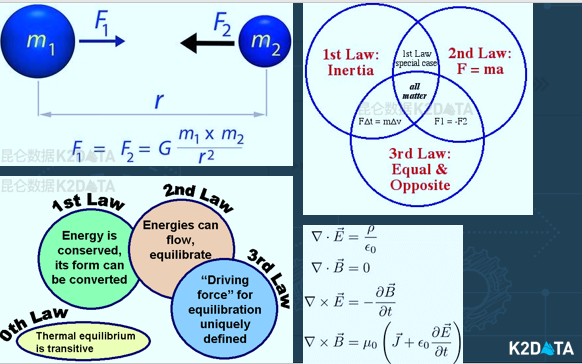
工业数据分析的特点
数据思维是从观察入手,先有数据,然后从里面总结pattern,找到它的规律,得到模型,然后进一步来预测。
但是我们在工业界常用的是右边演绎法的思维模式。先有理论,然后再把理论衍生出各种各样的推论,再由这些推论去指导,做各种各样的机器、实验,最终反过来验证一个做法是否对,如果不对,再去检验前面这些理论,前提假设,有哪些不合适的地方,进一步来改进。
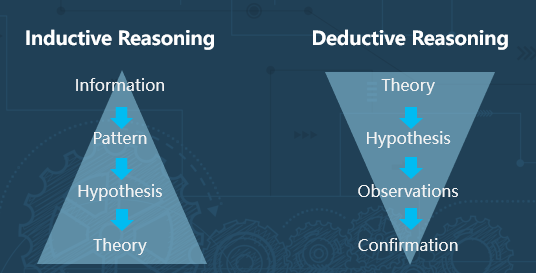
左边归纳法,是数据科学是这样的一种模式,右边是演绎法,是工业常见的一种思维模式,但这两者真的是一个冲突的问题吗?
举例:开普勒行星运动三定律的发现,是在他老师大量的行星运动观测的数据基础上(开普勒很幸运地得到了著名丹麦天文学家第谷·布拉赫20多年所观察与收集的非常精确的天文资料),总结出来第一椭圆定律,第二面积定律,第三调和定律。
实际上开普勒所总结的三定律,就是现在数据科学所做的,在大量的观测数据里面,总结一些规律,总结一些模型,而到了牛顿手头,把它升华成一个自然法则,然后才让它具有了更好的普适性。
一门科学发现的过程,是归纳法和演绎法交融的。
很多科学的新发现,新定律的提出,都是基于现实中发现一些新问题,然后通过数据归纳出来一些现象,再进一步提出假设,去验证理论。
所以归纳法和演绎法的两种思维,都是科学方法论的一部分。只是比如互联网金融大数据,不涉及到机理,更多用的是归纳法来总结数据的规律。而在工业界,有成熟的物理学、化学定律来保证工业系统的正确性。
但是工业大数据的价值恰恰是在两者的边界上,现在物理化学机理解释不够完善的地方,从微妙的异常数据现象里,怎么去发现问题,怎么去结合工业机理,去解答问题。
案例1:工业数据分析中的辛普森悖论
来看一个抽象的例子,在工业现场非常常见,叫辛普森悖论。






