
后台跑了模型,例如他会给一个分类的建议,613度是一个良品不良品的划分的区间。这个问题到这就结束了吗?这个图可以看出:实际上无论是良品还是不良品,他们都存在双峰分布,双方分布还恰恰都跟另一个良或不良的主峰是重叠的。
根据上面提到的辛普森悖论的例子,实际上双峰分布,肯定会有第2个因子,在影响这个产品的良率。
例如我们大胆的做一个猜测,原材料的耐热性可能有差异。耐热性好,温度即使高一点,也会得到良品。也有可能是另外一个因子:例如某些测量不准,有偏值,这都是潜在的因子。
这些是当前数据分析里没有体现出来的。
接下来再进一步分解,就可以找到更多的真正影响产品良率的因素。
当我们去看整体的温度分布,就会发现整体的温度分布,实际上落在了一个更大的区间内,它整体上呈现是一个近似正态分布。
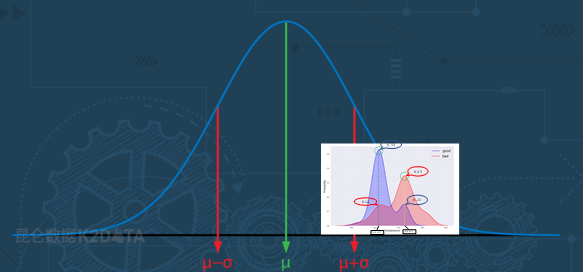
而这次实验拿到的数据正好是在它温度偏高的地方。实际上对于工业过程而言,温度过低过高都会引起不良。
基于这样的温度分布,我们又可以去猜测,对称的在低温的区间,假设我们做一组实验温度过低也会产生这样的一个产品不良的现象。
为什么温度分布是这么大的一个范围?
事实上这就有可能是第三、第四、第五个因子所引起的,例如在操作过程中,有些人设置的偏高,有些人设置的偏低;或者传感器的安装存在问题;可能却冷却系统做的不到位。
如果我们单纯的从原始温度数据的分布去看,你看见的就一个正态分布,但当你把背后的因子一个个的挖出来的,你能够更全面的看到这个温度是怎么产生影响。
温度分布有这么广的一个范围,是不是存在着季节性的因素,是否存在环境的因素,人为的因素?这些会作为影响温度的因子的第2级因子,按照故障树的因子分解方法,我们把工业现场一个个影响因素的问题,做一层一层的分解,把最初产品良率的大问题,分解成解决一个小问题,例如:去解决一个产品耐热性的问题;去人为控制温度的稳定性问题,最终你会看到温度分布的这条曲线会变成越来越窄,方差越来越小。
当管控区间不变的情况下,方差越小,过程能力越强,过程能力越强,就意味着良性生产率一定会得到提升。
所以真正解决现场问题的时候,一定要这样抽丝剥茧,注意到数据里面的异常点,才有可能从数据里面,真的把工业问题给挖出来。
作为数据分析,我一开始也不是工艺专家,并不知道对工艺过程影响的这些因子会有哪些?通过把工业现场的问题,背后对应的机理结构化的总结,来配合数据分析的过程,就可以发现一些新的事实。






