
知识管理
过去大家讲的知识管理大多是如何实现企业内部不同部门间的文档共享。例如做过的类似案例、类似行业,怎么能实现内容的沉淀,在文档共享的基础上还可以做知识地图,方便检索。
在文档之外,针对一些例行事务,通过个人或团队完成,也总结出知识分享的模式。比如报销处理等规章制度的知识管理。而例如开发等需要团队合作才能完成的工作,需要功能性的、流程性的、标准性的协同工作模式。再复杂一点,很多科学发现是专家工作模式,更强调个人的技能、专长和聪明才智,这时候的知识分享,是专家内部领域之间的切磋。这个层面的知识传承依赖于知识本身是例行的还是复杂的,工作本身是个人能完成还是集体能完成的。
知识管理,需先把外部显性的知识共同化,大家对一个事务都有理解,通过共鸣形成外化的知识,虽然这个知识当前还是隐性的,但实现外化的知识能够明确的辨析概念与内在关系,逐渐结构化或系统化,形成总结之后,最好还能从显性知识变成每个人的内化知识,从内化到共性化到外化到结合化,形成迭代循环,实现一个企业/组织知识的沉淀螺旋式上升。
知识工程
比知识管理更强调形式化,怎么把一个专家经验,能够以条理化、形式化沉淀下来。做知识工程的总体原则有一个框架。
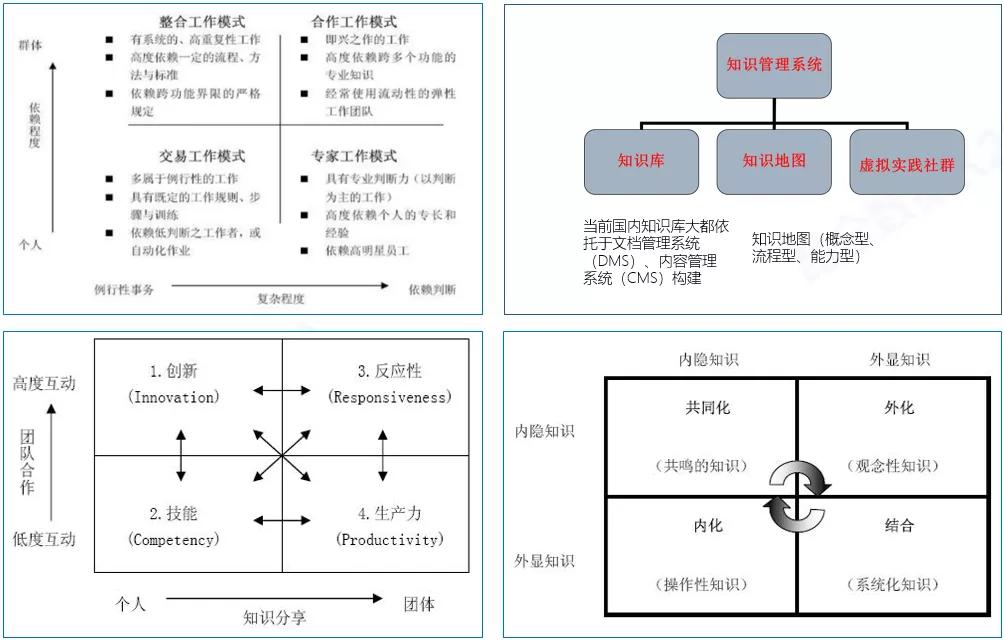
第一步,sources of knowledge知识的源头在哪里,一般来自于专家或者内部团队的经验。
第二步,有了知识源之后,知识本身不能流动,而是通过一定的方法knowledge acquisition,把它诱导出来。
第三步,knowledge representation知识的表征,怎么以形式化、概念、属性、数值、关系的形式表征出来,以树状结构、以各种模型把它形式化出来。
第四步,有了模型表征之后,knowledge validation知识的验证,专家知识不一定完全对,也不一定完备,经过数据大量实践之后,要做验证测试,不断完善knowledge base知识库。
第五步,知识库explanation justification,基于大量知识,可能会发现一些现象,会做一些研判,并进一步推理,可以是归纳推理也可以演绎推理。
这些是知识工程的一些核心要素,怎么做知识的捕获、知识的推理、知识的验证,来保证知识的有用性、可用性、实用性、重用性。
专家系统
知识工程最核心的是怎么把知识以非结构化的方式从行业专家脑子里提炼出来。80年代到90年代,结合专家系统有很多探索,这里面有三个最有名的工作。
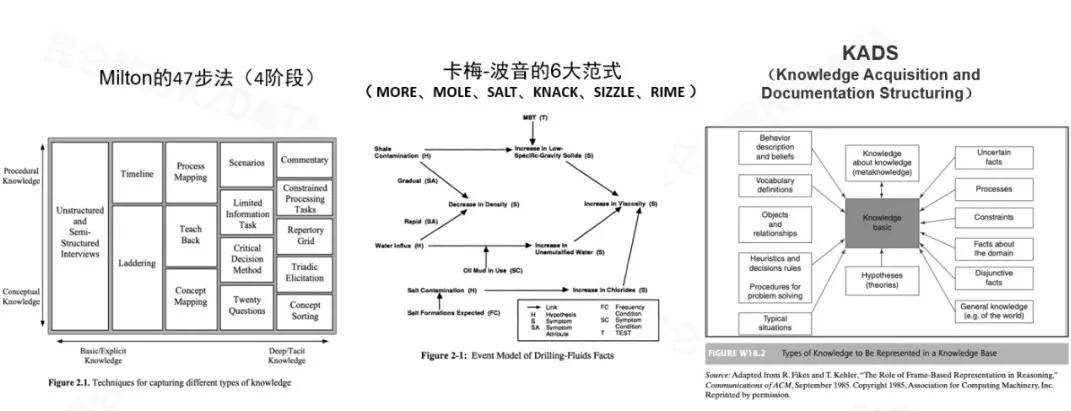
一是卡基梅农和波音公司成立了合作研究中心,对工业典型的诊断问题和一些预判问题,做了很多总结,提出了六大范式,针对六大类问题提出了很多方法论例如MORE SALT等,基本上是针对一种知识,怎么来保证知识的无歧义和完备,他们提出了很多形式化建模方法,这里面有很多不错的工作。
二是KADS,欧盟支持的一个项目《知识获取与文档结构化》,对知识沉淀方法也做了类似总结,特别是把知识分为约束、事实、过程等很多要素,目前在欧盟用的最广的当前版本是common case共同性的案例,但是在细节上不如卡梅-波音做的细。
另外Milton有本专著,根据不同的知识的类型、知识沉淀的方法做了总结,有的是通过一些非结构化访谈,有的是通过process mapping流程地图,有的是通过communication专家访谈等方式进行了总结,分成47步四个阶段。
知识沉淀的过程非常困难,困难的本质在什么地方?根据过去经验,大概总结为四个方面:
第一,知识本身的产权很难界定一个老专家真正能把故障诊断经验总结成知识,可能需要10多年或者整整20年的经验积累,不断的用悟性总结,但一旦分享出来,可能只需要很简单的几天就能学习到。知识沉淀者得到的权益和他的付出成本是不对等的。
第二,从技术来看,专家经验其实并没有那么“美”,大部分时候专家经验没有结构化,也没有定量化,造成了到现实中也很难用,很难完备。
第三,知识沉淀的过程非常困难,知识不会自己流动,现阶段,专家自主沉淀知识还是有一定技术门槛,需要不断的诱导、不断的去循环、不断的交互,才能获得。如果分析师对这个领域不太熟悉,很难获得深层次的知识。专家把脑子里的知识转化成语言,本身就有损失,通过语言传递给分析师,进行再次加工和解读,再去沉淀,中间会损失很大一部分信息。
第四,如同西屋电气的例子,看起来非常简单的一些诊断逻辑,需要1.6万条规则,为什么需要1.6万条,其根本在于专家规则这种表达形式的推理能力非常有限,规则经常“if then”,所谓的推理基本上就是条件的触发,这种规则的推理能力非常弱。
如果表达一个研判,规则目前是最实用的一种方式,但也许不是最经典的。规则的表达能力很有限,缺乏推理能力,而现在机器学习、人工智能最大的问题还是表达能力,在此之上能不能做更深层次的推理,能不能推出来在目前认知和数据情况下存在的一些现象,这是我们目前面临的一大困境。
大数据能为知识结构化带来什么
第一,量化评价检验专家经验的可信度,到底对不对、在多大程度上对;同时,可以非常定量的评价专家知识的效果。实事求是地讲,很多专家经验描述有模糊性,有传递损失,这个认知如果原封不动的用大量数据验证,会有不少的虚假预警,这个我们在过去经常发现。也因为专家知识非常模糊,用到现实效果怎么样也没有定量评价,就很难给专家合理的回馈。有了基于大数据验证的定量评价之后,使用前和使用后到底效果上有多大改进是可以评价的,才有可能实现利益的度量和分配。
第二,大数据为结构化提供了技术基础。有好多专家知识在表达的时候,隐含了很多前提条件,隐含了很多场景,也有意无意的可能忽略了一些信息。真正原封不动百分百的形式化之后,会发现好多场景没有覆盖。有了大数据之后,因为一些样本覆盖空间比较大,我们可以发现一些反例,可以反过来让专家补充自己的知识,也可以不断的在专家基础上细化一些知识保证完备性。此外,如果工艺参数发生变化,大数据还能保证知识可演化性。
第三,大数据可以保证知识的大规模应用部署。知识沉淀出来之后能不能有效果,要看能不能自动化部署。有了大数据之后,以工业app的颗粒度实现自动化部署,可以知道这个模型/这个规则运行多少遍,有多少次对有多少次错,可以更好的贴近业务价值创造过程。例如可以进行实时自动提醒,用户在遇到问题的时候,可以提供一些参考案例或者类似案例,可以做决策支持。过去通过人工的方式,只能先变成内化成自己的一些经验,靠人去现场判断,靠人去推动一些变化应用到业务流程,这中间有时候还掺杂了一些新的变量,很难大规模应用。
观看视频版,请移步B站-昆仑数据K2DATA。
服务
Copyright@2025昆仑智汇数据科技(苏州)有限公司 版权所有
北京市海淀区中关村东路8号东升大厦B座805AB
