
问题背景
研究对象是在露天矿场里进行土方作业的电动矿卡,希望采用数字化的手段,分析现有矿卡工作过程中上传的数据,提高矿卡的工作效率以及单位时间内矿卡运输的趟次,以精益的调度运营来增加营收。这是一个长期目标,需要分阶段来实现。
第一阶段的工作是为长远目标打基础,想要提高运行效率,首先要通过矿卡上传的状态数据,像位置、速度、电机的输出,当前的档位等等,把矿卡的工作流程做一个数字化的呈现和切分,然后提取对运营效率有影响的一些变量指标,比如等待时间、运行速度等进行相关性分析。
当前主要数据来源是Tbox上传的数据,采样频率目前是每10秒一次,还有一些其他的辅助数据源,经过清洗入库之后由分析模型在模型层提供一些分析服务,支持下面这6个计算应用。下面报告所涉及的主要工作是模型层中的矿卡状态分析。
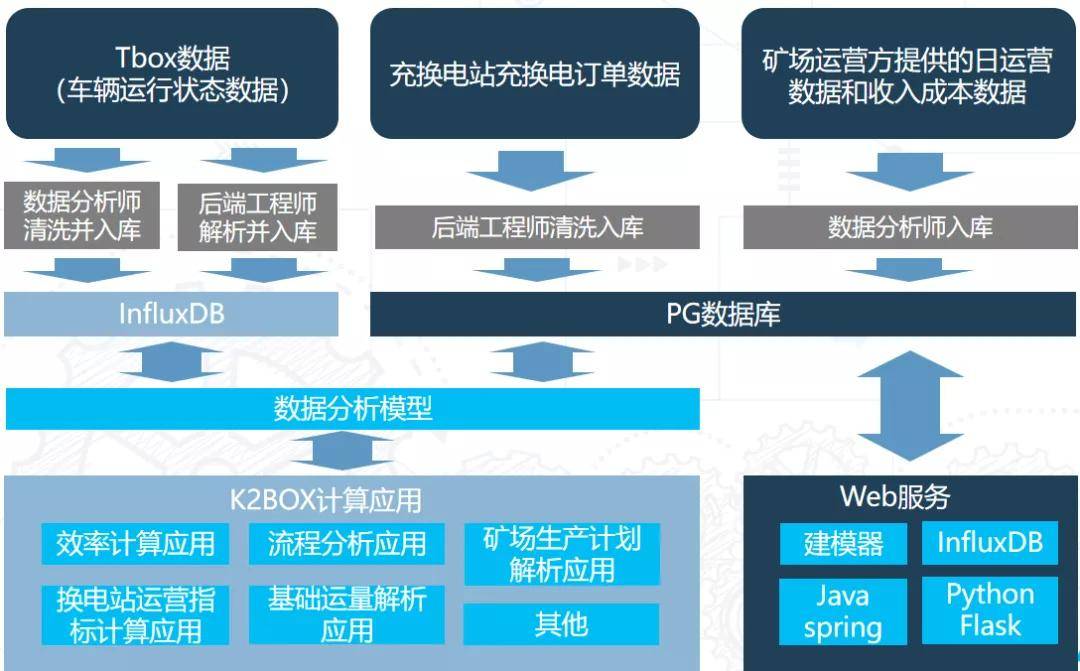
矿卡的工作流程及作业中的主要特点
矿卡在矿场上进行土方作业,典型的工作流程是在指定的装载区进行装载,装满后运到卸载区,完成卸载,再回到装载区进行下一个装载循环。
另外由于是电动车,装载来回几趟之后,需要去专门的换电区进行换电作业,所以存在另一种典型的工作流程模式:在完成了某个循环之后,先去换电区进行换电,之后再重新开始装载流程。
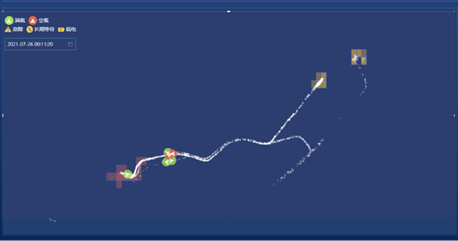
虽然应该只有上述两种流程,问题看起来好像比较简单,但实际还是有一些问题需要处理,例如下面这张图是某段时间内,矿卡在矿场里的运行轨迹,可以看到轨迹经过了多个作业区,其中可能有多个卸载区,甚至可能有一些修路的卸载区,因为矿场的路都是用土夯实的,有时候天气不好导致路面受损,需要临时运土过去修路。在分析过程中要排除掉这些因素的干扰。
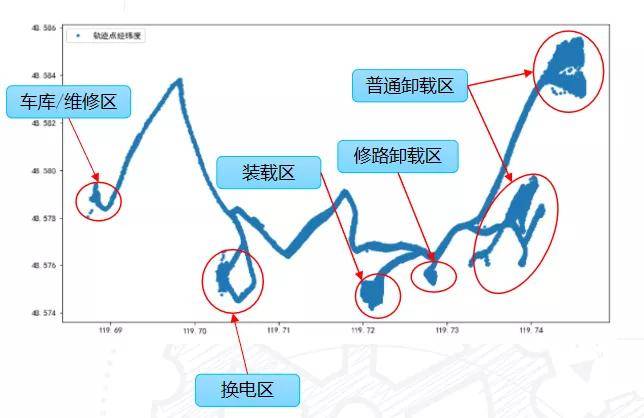
另一种干扰因素是工作区的位置范围是不固定的,会随时间有一定的变化,比如说装载区,随着挖土的进程,肯定是有一个缓慢移动的过程。卸载区也会随时间发生一些变化,比如说一个卸载区堆满或者有一些管理上的规定,可能就会换一个厂区进行卸载。
一是可能有多个工作区,另一个工作区会随时间发生变化,是我们在分析过程中需要考虑的主要问题。
模型的输入与输出
模型输入是从 Tbox为主要来源采集的矿卡位置和工作状态等数据,要得到的输出是对矿卡的工作流程进行分析,分析结果可能包括这么几个方面:
一是工作循环的切分,从这一次装载、卸载到下一次装载,算是一个基本工作循环,每个工作循环的起止时间和循环内车辆的装载状态的变化过程。
二是整个工作循环内,矿卡在哪些工作区域进行了作业,可以从中提取出一些循环效率相关的指标,比如在各个工作区的等待时间、途中的行驶时间、行驶速度,这些指标可为后续的循环优化提供数据依据。
三是在循环内的车辆的健康信息,为车辆的维护维修提供一些参考信息。
数据分析的基本思路与尝试
有了输入和输出的定义,整个数据分析模块的工作就比较明确了,有两种基本思路。
第一种思路,也是最直接能想到的做法,是找到车辆每次循环的状态变化的过程,从状态数据里面,去推测矿卡的装载状态,继而去切割它的工作流程。
但按这个思路去做了一些验证,发现不太可行。
首先车辆的载重状态没有测点,同时也不具备安装载重测点的条件,无法直接通过载重来判断满载或空载。
那是否能通过其他的一些变化去判断它的状态?比如从电机的输出与车辆的速度变化,或者从档位的变化与速度变化之间的关系,能不能推测车辆整体的重量状态,进而去推测它的装载状态?尝试发现这也比较困难,因为现场的工作条件比较恶劣,坑坑洼洼的土路居多,车辆在运行过程中不平稳,状态起伏非常大,影响判断的因素也会比较多。想从简单的物理模型的角度去做载重状态分析很难。
既然因素比较复杂,那能不能直接学习出一个模型呢?但学习又遇到缺乏标签的问题,因为拿到的数据没有标明哪一段是空载状态,哪一段是满载状态,还需要从数据里去推断它的状态,给训练数据提供标签,但这本身就是一个比较大的工作量,权衡之后我们考虑换一种思路。
第二种思路,从工作区域的角度出发,首先从数据里把各个装载区、卸载区等这些工作区域的范围定出来,再根据车辆在不同的工作区之间的轨迹,经过了哪些工作区去判定车辆的工作流程。
从工作区域间接判断运行状态,也可以为后续用车辆状态去判断空载满载积累一些标签数据,便于后续算法的升级。
基于以上思考进行数据建模,从工作区域的定义出发,先在原有的实体基础上增加一个与工作区域相关的实体——地块节点,地块节点是将矿场画出一系列的小方格,每个小方格成为一个地块节点,由这些地块节点组合形成工作区。
通过矿卡在各个区域内的一些状态的统计特征,给工作区域打标签,是装载区、卸载区、换电区或者车库,然后通过矿卡的位置,结合对工作区域的定义,得到矿卡的工作路径,继而去判断它的工作状态。
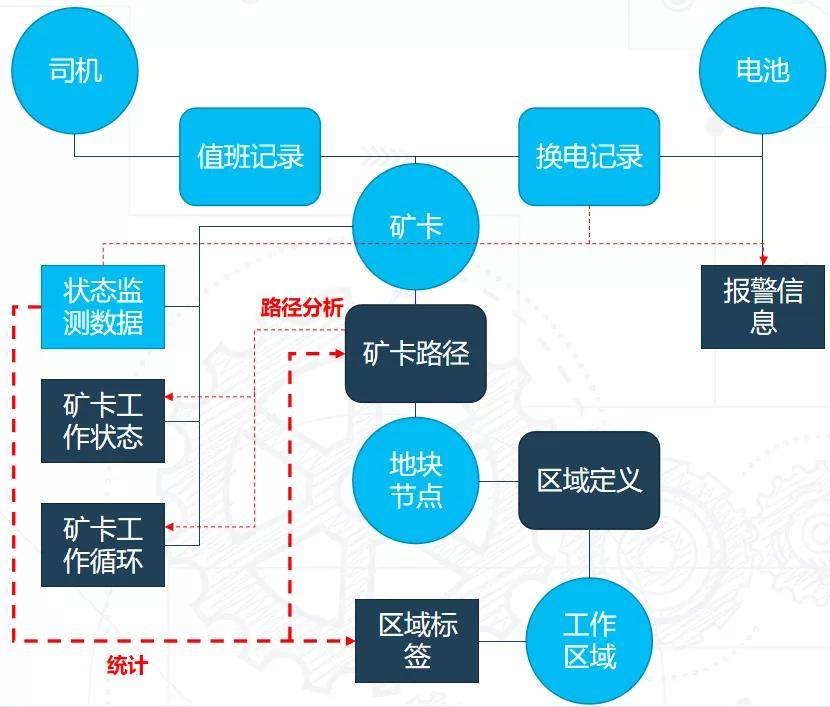
我们进一步把上面的数据实体定义详细设计成了在开发过程中的数据表,基于整理后的数据模型,就可以进行矿卡总体的分析流程。
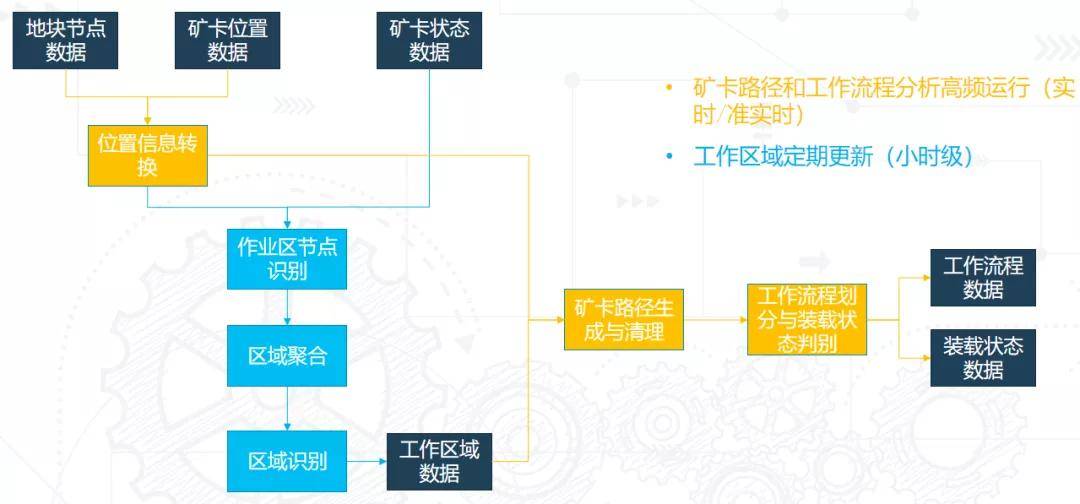
考虑到矿卡的工作区域会随时间发生变化,所以整个算法流程分成了不同频率运行的两部分,一部分是以较低的频率运行的工作区域的识别部分,是小时级的,比如一小时或者两小时进行一次新的工作区域的识别,来更新整个矿场内的工作区。
这里面包括有4个步骤,首先是对地块做离散化的划分,同时把 GPS得到的矿卡的位置数据转换为它经过的地块节点的序列;之后通过对各个节点内的状态的统计分析,去识别潜在的作业区的节点;再将作业区的节点聚合成作业区的区域;然后通过各个区域内车辆状态的统计分析,去识别这个区域具体是什么样的区域。这个过程就完成了对工作区域的定义。
另一部分是在工作区域定义的基础上进行比较高频的实时或准实时的工作流程分析。首先也是把矿卡的路径通过位置转换到节点序列,然后结合区域定义,把它的路径进行生成和清理,之后根据路径去做工作流程划分以及装载状态的判别。
最后得到两方面的数据,一是工作流程的划分数据,每一趟什么时间开始的,什么时间结束的,它是一个普通的装载卸载的流程,还是中间有换电的流程。另一方面是对车辆的满载和空载状态的判断。
流程实现算法的详细介绍
首先是地理节点的划分和位置信息的转换,我们把整个矿场按经纬度进行离散化,划分成一系列的小方格,方便后续进行区域的定义和整合。
每个方格的尺寸都是55米×55米,大概就是相当于4辆矿车的面积。这个尺度主要考虑两方面的因素,一方面考虑分辨率画的不能太大,否则整个分辨率会不太好,会把一些不相关的节点划到工作区里;另外考虑实时计算的压力,因为对位置信息转换需要做到实时运行,如果节点太多,则会影响整个程序运行效率。
综合考虑之后,对矿场的划分做了55×55米的尺寸,然后根据矿卡的GPS数据,结合对每个方格的定义,把矿卡的轨迹转换成为地块节点编号的序列。
有了上述的基础,可以做作业区的节点识别,看哪些地块节点是可能的工作区。这里需要考虑工作区节点与其他节点的区别在哪,矿卡到了工作区节点的行为模式跟在其他比如路上的行为模式不一样,比如到工作区之后,它有一个停车的过程。停车之前往往会挂倒档,不管是装载还是卸载,都需要先倒车一段时间到指定位置之后,才会进行相应的作业,所以要找出一些带特征的作业动作。
考虑到这些原因,我们对每一个节点进行统计,一段时间内矿场所有车辆在这个节点里的行为特征,比如停车前挂倒档的比例,比如货箱的举升器的状态统计等等,把这些特征统计出来,作为每一个地块节点的特征,然后用分类模型去看哪些可能是作业区节点,哪些不是作业区节点。
在这一步我们设置了一个判定原则,就是做节点判断的时候,尽可能全的把可能的节点包含进来,允许一部分不是作业区的,被错误归进来。
得到了潜在的一些作业节点之后,把节点聚合成区域,把它定义成一个工作区。这个工作区域是通过节点的相邻关系去定义的,一组相互之间有相邻关系的节点,定义为一个区域。
通过聚合得到这一系列区域之后,再看矿卡在这个区域里的行为模式,来给这个区域打标签,判断是哪一种类型的工作区域,比如装载区、卸载区、充换电区和车库。这和刚才地块节点的原理类似,对多个节点构成的区域做车辆的行为统计,作为每个区域的特征,还是建立多分类模型,把工作区域划分成这些具体的功能区。
在划分完成之后,得到工作区的分布情况,可以注意到有一些Other其他区域的定义,之前在节点识别里,把一些非工作区的节点识别进来,后面发现它并没有实际工作区的特点,所以又被划分成other。
整体想法是在选节点的时候,条件放宽,在工作区识别的时候再做严格识别,把可能不是工作区的地块区域再排除出去,达到尽可能地不漏掉实际的工作区的目的。因为如果在工作区识别有遗漏,那么最后的整个工作流程的切分,误差就会非常大。
得到了工作区域的定义之后,就可以生成矿卡的整个路径,根据工作过程中位置数据给出的经过的节点序列,整理成经过的工作区序列列表,之后进行清理工作。
为什么要进行清理?主要跟矿卡的工作模式有关。
前面讲到矿卡的典型工作流程,一般装载完之后只会去一个地方卸载,也就是说矿卡路径的两个相邻装载区中间应当只有一个真正的卸载区,同样在两个卸载区中间 也应该只有一个真正的装载区。但是在真实的卸载区域的途中,有可能会途经一个卸载区或者途经一个装载区,清理的目的就是去把这些途径的工作区域排除掉。具体做法是对工作区域的序列做一个分析,对中间每个区域的特征做一个评分,然后取评分最高的那一个作为它的真实区域,去掉途经的工作区的干扰,留下真实的作业区。
取评分最高的设置,主要是为了保证最终肯定能取到一个真实的,如果还按分类模型来做,有时候数据缺失或者其他问题,会导致特点都不太典型,最后都不能被判定成真正的工作区,那后续的流程也就无法进行了。
清理完工作路径,就可以很方便的进行工作循环的切分,比如以装载区为基准,以车辆每次进入装载区的时间作为它工作循环的起点,到下一次进入装载区作为终点,就可以确定车辆的基本循环,进一步也可以识别车辆状态。
比如说进入装载区,车辆会从空载状态变成满载状态,到卸载区,从满载状态变成空载状态。这里涉及的主要问题是识别状态变化在哪个时候发生的,也就是在区域里找到实行作业的停车点,停车点的识别考虑三方面的因素,车辆停车的状态、停车前的档位状态以及停车后的加速状态。
通过综合判定,从区域里可能的多个停车段中找到最像作业停车的那一段,然后以停车时间作为分割点,比如卸载区停车前是满载状态,之后是空载状态。
通过以上算法流程,实现了对车辆状态的分析,对工作流程的划分,以及空载满载状态的区分,及途中运载过程的报警信号,像电池的电量信号,电池的报警信号等等,可以支撑将来整个应用系统的实现。
下面这几张截图中,这张图给出的是矿卡实时运行的分析页面,白色的是近一段时间的运行轨迹,这里的箭头是每一辆卡车的位置,通过色块标明了工作区域,红色的是一个装载区,橙色的是两个卸载区。同时,模型给出了工作循环的划分结果,跟矿上设置的打卡的结果进行了相互验证,总体的准确率能够达到90%左右,可以满足实际应用系统的精度要求。
总结
这段工作主要是电动矿卡工作过程中,基于Tbox等数据源采集的车辆状态、位置和报警等一些数据,建立起了电动矿卡的工作流程的分析模型,来识别矿卡的工作状态,切割工作流程,为矿卡运行的调度优化提供一些基础的数据和信息。
这里采用以工作区识别为基准的方法进行工作流程的分析,以矿卡在各个地块节点内的行为特征来进行工作区域的筛选、聚合和识别,把工作区分为各个装载区卸载区等特定区域。然后利用区域的识别结果,结合车辆的定位数据,得到它的工作路径,清理后得到最终的工作流程,进行工作循环的分割,然后分析车辆状态,最后的结果能跟矿场提供的打卡结果形成相互验证。
服务
Copyright@2025昆仑智汇数据科技(苏州)有限公司 版权所有
北京市海淀区中关村东路8号东升大厦B座805AB
