
数据可视化是非常基础、却也非常重要的数据分析手段,尤其在数据探索阶段,通过“恰当”的可视化分析,有效发现数据规律或问题,与业务知识进行交叉验证,可以确定下一步分析的方向和手段,是数据分析中非常重要的一环。
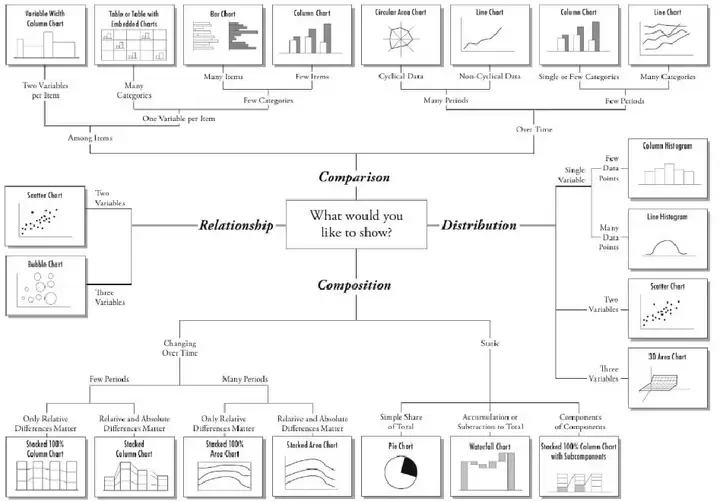
上图是对于四大类常用可视化图形的经典总结:比较、关系、组合和分布。本文不就此展开说明,对于数据分析师而言,当面临一个具体的业务问题时,可视化只是达成分析目的的其中一把工具,不能只停留于画出一个漂亮的图,分析的重点是如何从可视化图形中发掘数据分析的线索和思路。
如何选择坐标轴?
下图是一类最常见的市场分析报告里的图:绿色代表自身产品,黄色代表竞争对手的产品,紫色代表市场平均水平。请问:左边和右边的图,哪个是正确的?稍微仔细一点看图可以发现这个问题很奇怪,因为左右图的数值是一模一样的,而仅仅是坐标轴不一样——那有何正确之分呢?
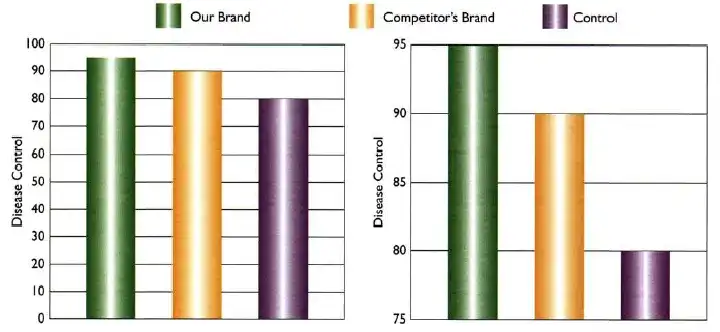
对于市场分析图表而言,按照行规一般都得保证坐标轴是从0开始,或者是固定最小最大值,以保证类似图形的比较是统一标准的、以免传递混淆的信息。因此,对于市场分析报告而言,左边的图形才是正确的可视化方法。但是服务于不同目的时,正确答案也会不同——右边的图形通过改变坐标轴,使差异变得更明显:对于试图分析和发现微小差异是非常有帮助的。在数据探索阶段,通过适当地放缩坐标轴,可以更有利于发现数据中的主要矛盾。
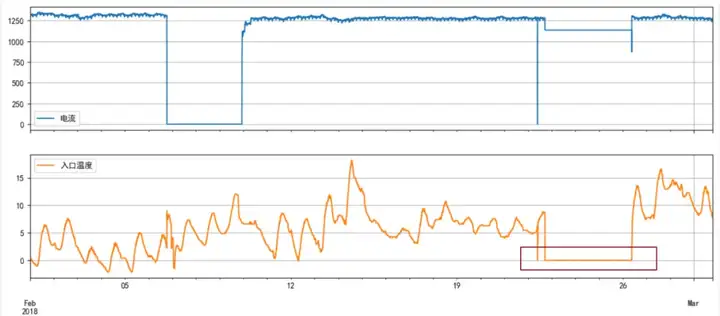
以最基础的折线图为例,下图是某空压机3年多的电流数据,我们能看出:在三个橙色框的时间段内,存在明显的数据异常;而在其他时间段内,空压机运行整体比较稳定:电流数值基本都在1200-1400之间。
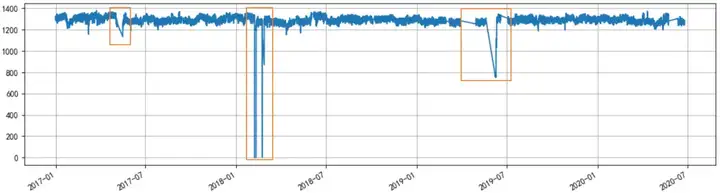
那这三个时间段内究竟发生了什么呢?通过对X轴的放缩,并结合其他测点如流量、温度、振动等数据,我们可以确认:
· 第1和第3个橙色框内,所有数据都空缺。以第一个框为例,结合电流和进气量数据进行可视化,可发现其数值是逐步变大的,说明这是一次停机(如大修)后的正常启机过程。如果主要分析目标是稳态运行,则启停时段的数据需要被手动或自动滤除。
· 而第二个橙色框的电流数据是突变到0;且在2/22~2/26这个时间框内,温度也突然变为0。众所周知,温度是一个慢变量,空压机的入口温度基本等于环境温度,不可能突变、也不可能长期保持0不变,因此第二个橙色框内的数据异常多半是由网络或数据库异常所引起。
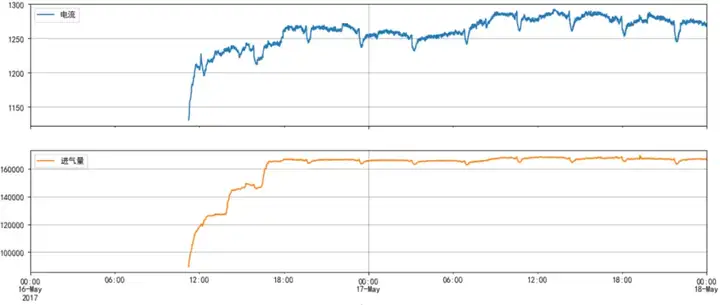
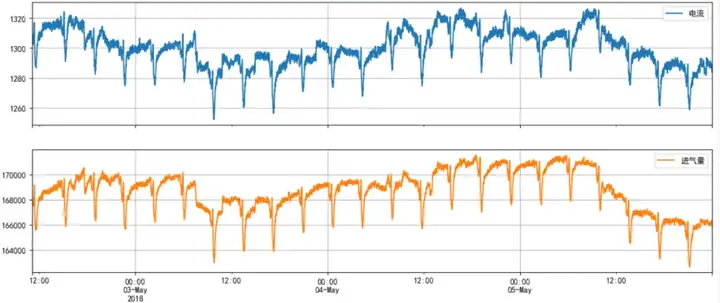
从3年多的历史数据发现这种全局的数据异常,还不够寻找分析思路,我们需要进一步缩放X-Y轴,以寻求更多的信息,还是以电流和进气量为例,放大后可以发现:
· 负荷本身并不是那么稳定,依然存在基本按日为周期的整体波动,随后分析需要考虑如“每日气温变化”等日级因素对空压机表现的影响;
· 电流和进气量每4小时就有一次突变,而且非常规律且同步:这是另一个重要的分析线索!在不同的时间段再三确认该现象的普遍性,且目前已知数据里也没有其他4小时的周期量——那意味着其背后一定另有一个关键因子。
通过与业务交流了解到:4小时的周期性波动,这是空压机正常工作时,由后续工艺环节某控制变量的定期动作所造成。然而我们的目标并非分析空压机的控制行为,而是通过其轴承振动和温度研究设备健康预警。作为重要的工况变量,电流和进气量的这种周期性波动,会大大降低可用数据的质量,影响建模精度。那如何处理呢?
· 一个想法自然是把背后的控制变量也纳入分析,但毫无疑问增加了非必要的建模复杂性。
· 第二个方法却更简单直接,因为主要考虑的是工况量和振动、温度等长期变化趋势及其之间的关系,4小时的周期波动相比健康预警的长周期也是可忽略的次要矛盾。因此,我们可以设置一个大于4小时的滑动窗口,通过中位数滤波提取电流和进气量的趋势信息,作为下一步分析建模的依据!
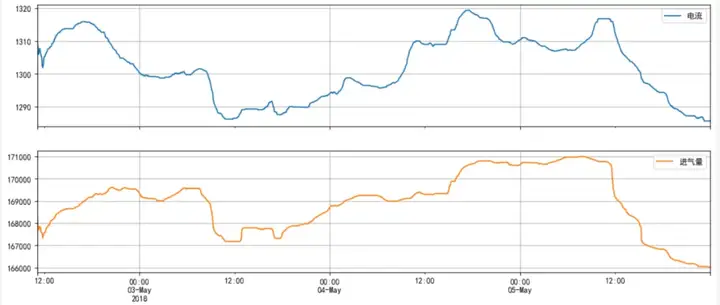
平滑后的电流和进气量如下图所示:平滑后的数据准确保留了电流和进气量的低频信息即趋势变化这个主要矛盾;损失的高频信息,对于后续的设备健康预警分析反而是有益无害的。
火眼金睛:从数据中发现线索
由上述案例可以发现,数据探索虽也是编写代码,但其目的和过程与常规编程并不相同,而更像福尔摩斯探案,从数据中发现细微的线索,逐步导向真相。可视化则是数据分析师人手必备的入门探案工具。
下面来看一个发光器件的功率问题,其终极的分析目标是如何通过工艺参数控制来优化功耗,即功耗是数据分析的目标变量Y,其分布图如下所示:我们从图中能读出什么信息?
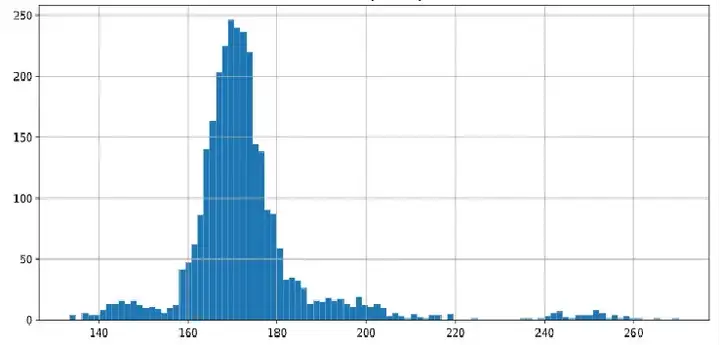
第一步:从数据分布看,功率数值分布于140~260之间,集中在160~180之间。有没有发现什么问题?作为一款产品待优化的重要指标,其功耗数据分布在140~260这么宽的范围是不正常的(注:功耗并非生产直接管控指标,因此没有相应的上下限管控,只能事后测试分析优化),而160~180这个主峰分布看起来才应该是其正常数值范围,我们找到了第一个线索。
第二步:进一步看图,可以发现左边140~160,右边180~200,240~260看起来存在三个次峰。事实上,原始数据里的次峰并没有如此明显,而是通过对数放缩坐标轴(即第一节所谈的小技巧)才发现的线索。这三个次峰是分析的第二个线索,与主峰如此明显的差异背后,一定存在某些未知的原因有待发掘。
第三步:在总功耗数据上无法进一步发掘信息,但由业务知识可知:总功耗实际是由红绿蓝三色光的功耗加和得到,而原始数据里也可以计算得到红蓝绿三色光分别的功耗,与总功耗一起作为4维变量,俩俩做出关系图(对角线是4维变量各自的分布图),并进行聚类可得到以下5类数据,其中:
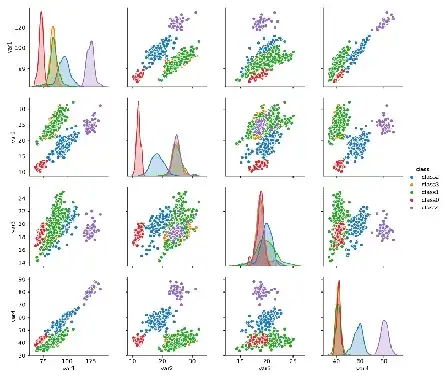
· 绿色簇正好对应于主峰超过80%的样本,主峰应该是进一步分析功耗和工艺参数关系的主要数据集。
· 紫色簇在第4维蓝光的数值比绿色簇正好大了一倍,红色簇在第2维红光的数值比绿色簇小了一半;其他两维都和绿色簇分布重叠。只有一维数据差一倍这么巧合,不太可能是自然发生的,是我们发现的第三个线索!通过后续的检测机台集中性和时间集中性分析确认:紫色簇和红色簇样本,分别是试生产过程中,由两台设置错误的检测机台在某段时间集中产出的,因此,可以非常肯定的将紫色簇和红色簇作为“异常”剔除!
· 而蓝色簇则在红蓝绿三维的数据分布上、与绿色簇的正常样本均存在较大差异:这是可视化分析发现的第四个线索。后续通过对原始数据的进一步关联分析,发现其来源于另一子产品类,所使用的材料体系不同,自然其表现不同,因此也应该从本次数据分析任务里剔除。
· 橙色簇的数据占比最少,约1%;没有明显的特点,关联分析也未发现其明显差异,因占比很少,所以直接作为“异常样本”剔除,也不会对接下来的数据探索造成影响。
上述案例充分展现了,如何通过灵活使用可视化分析,配合聚类算法等其他分析手法,从纷杂的原始数据里抽丝剥茧,发现和抓住分析的线索,排查背后的原因。事实上,本课题一开始多轮建模分析的结果很差,甚至出现了与机理经验相悖的结果(下篇将更详细论述),正是应了机器学习领域的经典语句:“Garbage in, Garbage Out”。通过上述可视化分析,找到线索并拆分出干净数据集,才成为了该课题的破题关键步骤。
结语
本文作为“可视化分析”上篇,展示了可视化如何作为“探案手段”,帮助数据分析师从数据中寻找分析建模的线索。作为数据分析师最基本、也可以说最重要的工具,通过适当的可视化手段,可以从数据中发现主要矛盾,排除次要矛盾,一步步引导数据分析师恰当的处理数据,寻找分析的思路,为后续的建模打下良好的基础。“可视化分析”下篇将就工业数据分析中最重要的“正态分布”展开探讨,探索正态分布是如何帮助数据分析师从数据分布的特点中,找到问题解决的关键思路。
服务
Copyright@2025昆仑智汇数据科技(苏州)有限公司 版权所有
北京市海淀区中关村东路8号东升大厦B座805AB
