
今天的主题是:工业思维如何去加持数据思维,真正让工业大数据的分析来为我们工业现场的实践来解决问题。
数据可视化的“技”“艺”“道”
数据之技
这是一个非常酷炫的数据可视化的图。
现在在网上有各种各样的数据分析工具,数据分析软件、 Python、R包、可视化的工具软件,都可以做出非常多漂亮的,给人强烈视觉冲击的图表。但这一部分我认为叫技能或叫技巧。
可以通过各种各样的数据技能和数据技巧,让大家能够更直观的看到这个数据背后的一些现象。
数据之艺
这是数据可视化的进阶的下一级,所谓的艺术。

这不仅仅是一个可视化的图,它通过颜色的强烈对比,让大家直观的看到了石油和黄金的价格的波动。
可视化做到这一步,可以被称作艺术。
数据之道
然后再往上一层,要讲的是道,这是一张非常有名的图。
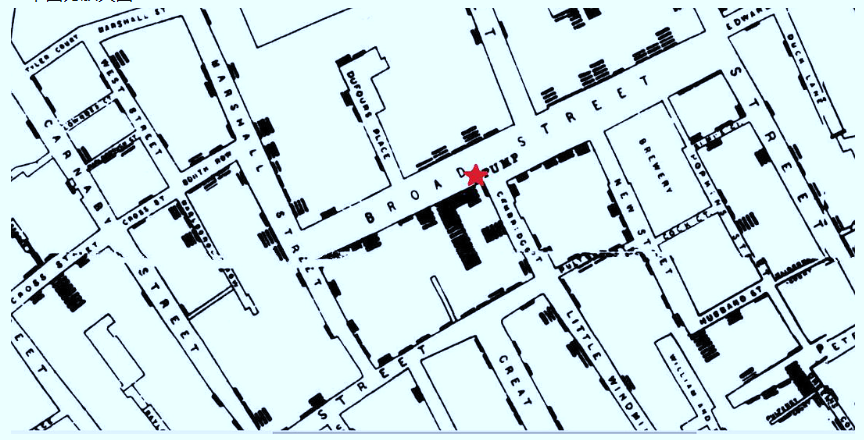
就如我们现在经历的疫情。这幅图也是有关疫情的可视化。
地图中这些黑点是这些发病统计的这个区域以及数量。而这个红点在这些黑点阵中的一口水井,这是当年在一个小镇上发生的疫情,然后来处理疫情的医生,通过这样的一个直观的可视化的手段,找到了疫情的一个关键点。
到了这个层面上,它直指问题的核心。找到这样一个结果,并不是说要用多么高超的技巧,通过这样一幅手绘的地图也可以发现问题。
实际上我最早想讲的一个主题是数据分析从入门到弃坑,打算讲一讲有趣的数据分析的技巧。后来觉得应该来讲数据分析的道,特别是工业现场实践的道理,能够通过工业思维和数据思维的结合,来真正解决现场问题方法论,而不是这些具体的技巧。因为现在网上有很多学习资源,在讲这些有趣的技巧。所以在这短短的直播里,来给大家讲一个数据的分析之道。
数据的分析之道
数据分析的技术
首先来讲数据分析的技术。机器学习大家都非常熟悉了,在过去20年是非常火爆的领域。
这幅漫画是对机器学习的一个评论:你在垃圾里面干什么?我在垃圾里面翻翻,直到翻出一些有价值的东西来。

这在一定程度上跟数据分析建模的过程,是真的差不多,因为我们并不知道我们能从大数据里面找到些什么? 直到我们找到一些认为有价值的,然后做数据分析。
数据技能,到了Alpha Go的时期可以称得上登峰造极。
最近李世石隐退,还下了让两子1胜1负,所以电脑围棋已经远远超过人类棋手的水平。但是电脑围棋距离真正的围棋还是非常远,即使强大如Alpha Go,也没有解决学围棋第1天要学的真子这么一个技巧。只是因为它现在的模型过于强大,你要诱发它出现一个错误的几率已经非常小。
何玉琪老师之前有一个叫 no Free lunch,没有免费的午餐定理。说的就是各种算法在普遍意义上它没有优劣之分的。实际上一个算法好,那是因为跟他问题的结构匹配的好,而Alpha Go能做得好,是因为它正好找到了匹配围棋这样的一个结构。
工业的基础
工业的历史实际上比数据科学要早得多。
所有物理学的大厦,后来化学、生物这些科学都是构建在这些科学定律的基础上,然后整个科学大厦,又构成了我们现代工业的基础。所有的机器,生产过程,产品,都是基于物理、生物、化学的这些定律所构建的。
工业数据分析的特点
数据思维是从观察入手,先有数据,然后从里面总结pattern,找到它的规律,得到模型,然后进一步来预测。
但是我们在工业界常用的是右边演绎法的思维模式。先有理论,然后再把理论衍生出各种各样的推论,再由这些推论去指导,做各种各样的机器、实验,最终反过来验证一个做法是否对,如果不对,再去检验前面这些理论,前提假设,有哪些不合适的地方,进一步来改进。
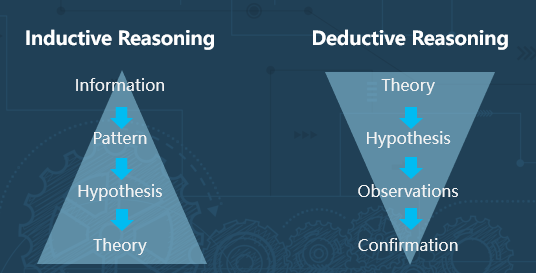
左边归纳法,是数据科学是这样的一种模式,右边是演绎法,是工业常见的一种思维模式,但这两者真的是一个冲突的问题吗?
举例:开普勒行星运动三定律的发现,是在他老师大量的行星运动观测的数据基础上(开普勒很幸运地得到了著名丹麦天文学家第谷·布拉赫20多年所观察与收集的非常精确的天文资料),总结出来第一椭圆定律,第二面积定律,第三调和定律。
实际上开普勒所总结的三定律,就是现在数据科学所做的,在大量的观测数据里面,总结一些规律,总结一些模型,而到了牛顿手头,把它升华成一个自然法则,然后才让它具有了更好的普适性。
一门科学发现的过程,是归纳法和演绎法交融的。
很多科学的新发现,新定律的提出,都是基于现实中发现一些新问题,然后通过数据归纳出来一些现象,再进一步提出假设,去验证理论。
所以归纳法和演绎法的两种思维,都是科学方法论的一部分。只是比如互联网金融大数据,不涉及到机理,更多用的是归纳法来总结数据的规律。而在工业界,有成熟的物理学、化学定律来保证工业系统的正确性。
但是工业大数据的价值恰恰是在两者的边界上,现在物理化学机理解释不够完善的地方,从微妙的异常数据现象里,怎么去发现问题,怎么去结合工业机理,去解答问题。
案例1:工业数据分析中的辛普森悖论
来看一个抽象的例子,在工业现场非常常见,叫辛普森悖论。
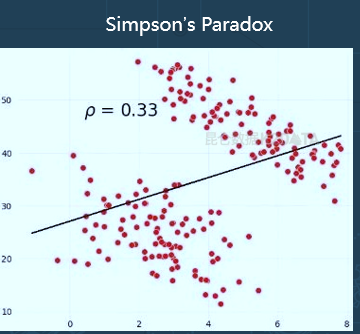
这组数据很简单,可以看出是一个正相关的关系。
假设你在解决一个工业现场的问题,做了分析的结论,去跟工业专家沟通,说找到了因子和质量之间的关系是正相关,工业专家会毫不留情的告诉你,对不起,我所了解的工业机理,他们一定是负相关。
这可能就会变成双方的一个gap。工业专家会觉得数据做的东西不可信,但是数据专家分析的过程没有问题,这问题在哪呢?
这个图可以很容易看到,数据它是分成了两个簇,当我们把它分到两个簇,再分别去分析,可以看到在每一个簇内,他们的相关性都是负的。
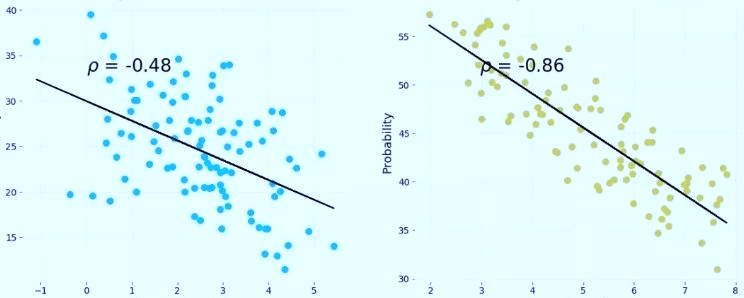
实际上数据分析本身没有错,问题的来源是有第三者。第2个因素没有考虑到当前的数据分析里面来,而这个因素可能是之外一个非常重要的因素,使得数据产生了不同的分簇。
这样一个简单的情形,大家肉眼也能看得出来问题,但是在现场做数据分析的时候,数据量非常大,数据非常复杂,它不是两个簇,是很多个簇,重重叠叠在一起,没办法靠肉眼去区分开。在这种情况下,有什么办法进一步往下走呢?怎么知道是不是有其他的因子在相互影响?
这就需要刨根问底,发现微小的异常,往下深刨。
案例2:质量分析的案例
常识科普:正态分布
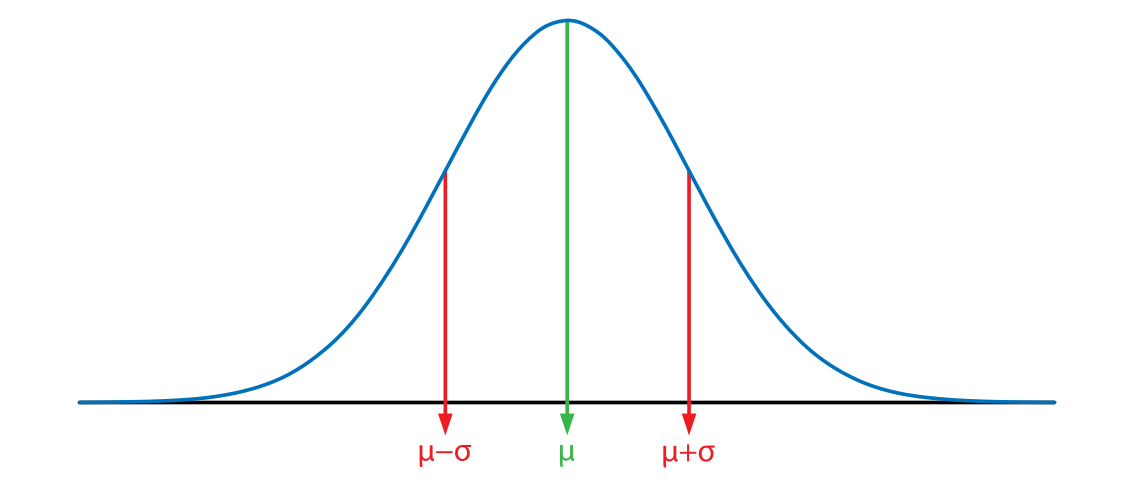
大家都熟知的六西格玛(6σ),实际上是把统计学的工具用到了工业现场来。六西格玛(6σ)所有的算法工具都是基于正态分布基础上构建的。
为什么要用正态分布,在工业现场为什么是正态分布而不是其他分布呢?
正态分布有一个叫中心极限定理,说的是如果你有很多随机变量的影响,被加和起来,最后形成的概率分布就会是一个正态分布。在工业现场,各种各样的影响因子非常多,很多因子不可控,例如人为因素,环境因素,所以一个生产现场非常关心的产品质量指标,一定是多因子影响的一个综合的结果。
工业现场都有人、机、料、法、环、甚至测量,各个因子综合起来,往往你看到的数据现象都是正态的,经常会看见很标准的正态分布在工业现场的数据里面。
这个案例是对某产品质量进行分析。从工业用户的角度来说,生产过程中的温度是产品质量的一个重要因子。
两条温度曲线,每一个周期对应一个产品的生产过程。
对于这个客户的问题是,他知道温度是重要的因子,但是不知道这个温度的因子到底是怎么影响产品质量的?
这里遇到了一个困难:每个温度周期实际上没办法跟产品的好坏来做关联。
我们要做的事情,首先是通过设计一些实验,让温度数据和产品的良率数据关联起来,然后再进一步分析。当时做了两轮实验,拿到了几百个样例。蓝色的部分是良品所对应的温度区间的分布。而红色对应的是这个不良品。这个看起来就是一个正态分布。

后台跑了模型,例如他会给一个分类的建议,613度是一个良品不良品的划分的区间。这个问题到这就结束了吗?这个图可以看出:实际上无论是良品还是不良品,他们都存在双峰分布,双方分布还恰恰都跟另一个良或不良的主峰是重叠的。
根据上面提到的辛普森悖论的例子,实际上双峰分布,肯定会有第2个因子,在影响这个产品的良率。
例如我们大胆的做一个猜测,原材料的耐热性可能有差异。耐热性好,温度即使高一点,也会得到良品。也有可能是另外一个因子:例如某些测量不准,有偏值,这都是潜在的因子。
这些是当前数据分析里没有体现出来的。
接下来再进一步分解,就可以找到更多的真正影响产品良率的因素。
当我们去看整体的温度分布,就会发现整体的温度分布,实际上落在了一个更大的区间内,它整体上呈现是一个近似正态分布。
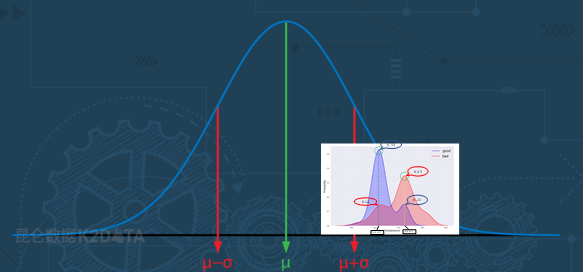
而这次实验拿到的数据正好是在它温度偏高的地方。实际上对于工业过程而言,温度过低过高都会引起不良。
基于这样的温度分布,我们又可以去猜测,对称的在低温的区间,假设我们做一组实验温度过低也会产生这样的一个产品不良的现象。
为什么温度分布是这么大的一个范围?
事实上这就有可能是第三、第四、第五个因子所引起的,例如在操作过程中,有些人设置的偏高,有些人设置的偏低;或者传感器的安装存在问题;可能却冷却系统做的不到位。
如果我们单纯的从原始温度数据的分布去看,你看见的就一个正态分布,但当你把背后的因子一个个的挖出来的,你能够更全面的看到这个温度是怎么产生影响。
温度分布有这么广的一个范围,是不是存在着季节性的因素,是否存在环境的因素,人为的因素?这些会作为影响温度的因子的第2级因子,按照故障树的因子分解方法,我们把工业现场一个个影响因素的问题,做一层一层的分解,把最初产品良率的大问题,分解成解决一个小问题,例如:去解决一个产品耐热性的问题;去人为控制温度的稳定性问题,最终你会看到温度分布的这条曲线会变成越来越窄,方差越来越小。
当管控区间不变的情况下,方差越小,过程能力越强,过程能力越强,就意味着良性生产率一定会得到提升。
所以真正解决现场问题的时候,一定要这样抽丝剥茧,注意到数据里面的异常点,才有可能从数据里面,真的把工业问题给挖出来。
作为数据分析,我一开始也不是工艺专家,并不知道对工艺过程影响的这些因子会有哪些?通过把工业现场的问题,背后对应的机理结构化的总结,来配合数据分析的过程,就可以发现一些新的事实。
从数据分析的角度,我们要做的不是沉浸于deep learning,先进的算法,提高模型精度,而是怎么去加持工业现场的机理,要首先对数据进行符合工业常识的筛选,才避免去做重复工。
纯粹的利用数据建模的过程往往会得到两种结果:第1种,辛普森悖论,你得到结论可能是跟工业认知完全相反。第2种,这个结论是一个显而易见的结论。那不用你去做任何的数据分析,工业专家也知道这个因子跟这个问题之间是什么样的影响关系。这种工作,没有充分利用你的 prior knowledge。
例如贝叶斯公式,都是从先验出发,得到一个后验。实际上先验是工业专家的支持,后验加持数据基础上得到了一些新的推论。
所以如果真正要去解决工业的问题,是一定要把这两者以一种合适的方式来结合在一起。不是说这边从数据出发,那边从工业出发,因为像现在我们看见这种双峰分布,就不是光靠温度的一个物理定律能够解释得通的,一定是要去思考背后的一些原因。
最后给大家做一些推荐。
例如:我想了解一下数据分析能做什么?应该看什么书?我不推荐专业书。
我这里列了三本书,都是非常有趣的书。






