
本文整理自清华校友工业数智化高峰论坛

工业互联网、数智化的核心是业务驱动,需要把工业业务场景、领域知识、经验和数字技术紧密结合在一起,所以工业大数据的本质是工业引领。
工业的不同业务环节都有数字化需求,但数据类型和业务场景的差异很大,昆仑数据在工业领域比较专注在生产环节,这是工业数智化的深水区。要做好这个环节,需要把生产现场的人机料法环测等各种数据有效收集管理在一起,同时通过智能算法结合工业领域知识,帮助工业企业实现生产提质、增效、降耗、控险等业务目标。要把数字化技术应用到现场去解决特定场景下的问题,有两个很重要的桥梁,一方面现场需要有足够的数据基础,数据要完整、要连续;另一方面,还需要结合这个场景下相关的领域知识比如说设备机理、生产工艺等等,才能做好。这两者在现实环境中挑战都很大。
生产环节工业数智化的两大核心挑战
数据方面,数据的采集、治理和组织,在现场都会面临很多问题。从采集的角度,虽然说现在工业企业对数据采集的意识比以前有了非常大的提高,但是数据到底应该在哪里采?以什么样的频率采?这个非常有讲究。
例如在煤化工行业,研究最关键的煤粉气化过程,就需要知道气化炉内温度,但是炉内温度不能直接被采集,只能在炉壁上安装温度传感器,根据气化炉温度场反算炉内温度,那么在炉壁上的温度传感器怎么布、布多少、如何换算成炉内温度,就有讲究,要结合热力相关原理。
我们也见过传感器分布的问题,比如在化工行业要做管道破裂预警,结果安了传感器的地方没有破裂,其他地方破裂,是因为装传感器时不了解管道中流体流动规律,没有装在管道受力最大位置。

数据采集起来之后,由于现场数据非常多,有设备传感器数据,还有原料的、质检的、环境的各种参数等等,如果只是散放在不同数据库里,使用起来会非常复杂,很难在同一时空下对齐。而这些数据在物理空间内,彼此之间是有逻辑关联的。如果能够把这些数据有机的组织在一起,能够反映其物理时空的逻辑关系,就会更利于数据消费。当然还有数据治理的挑战。怎么保证数据的完整性、准确性,以及标准化问题:不同的厂商制定的规范,不同版本控制系统下的测点名称,差异都非常大。还有怎么做数据的全生命周期管理的问题,例如十年以上的运行数据,怎么能够最高效、最经济保存起来,区分冷、热、温数据,都是从数据治理的角度要考虑的问题。
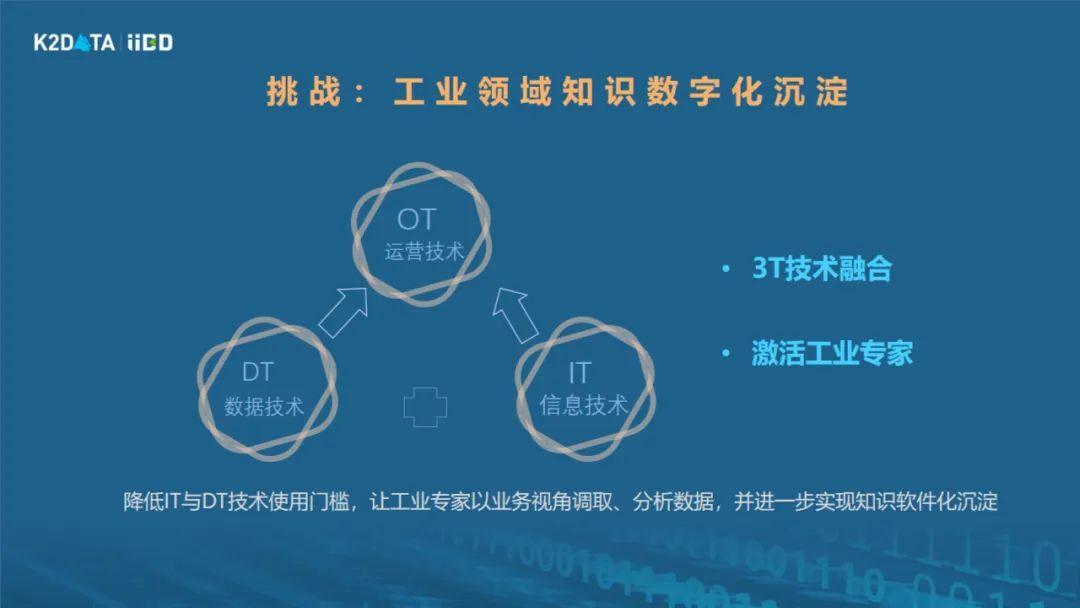
我们要解决工业现场的问题,意味着在采集数据、管理数据的时候,必须要结合对工业系统的整个机理和结构等方面的认知,需要先理解该领域下的工业知识。工业领域知识有一部分是已经沉淀下来的理论知识,但还有一大部分的知识没有被很好的形式化描述,是现场工业专家脑中的一些生产规律。
我们要做好生产系统的数智化,需要把理论模型、机理能够跟专家经验有机结合在一起,我们的经验来看,大概百分之六七十是机理,另外百分之三四十是现场经验。但是很多的现场经验,是定性不定量、模糊不确定的知识。我们如何能够把这些知识从隐性变成显性,从定性变成定量,能够用数据化的表达,变成软件,变成算法,这也是一个非常大的挑战。
生产系统的数字孪生--化整为零
面临上述挑战,在我们面对一个非常复杂的工业生产系统的时候,怎么做数字化呢?
刚刚讲两个核心的挑战,第一个挑战是如何有序采集和组织数据,建立起生产系统的数字孪生模型?关键就一个字——拆,再复杂的工艺系统都可以拆解成很多单元设备的组合。
比如水泥生产系统,主要工艺过程是“两磨一烧”,水泥生料先磨成粉,经过烧制成熟料,熟料最后磨成水泥粉。因此,水泥厂拆开,就是生料磨、熟料磨、煅烧窑,如果说我们再把磨、窑炉这些主力生产设备再拆开,就会有电机等通用设备单元。
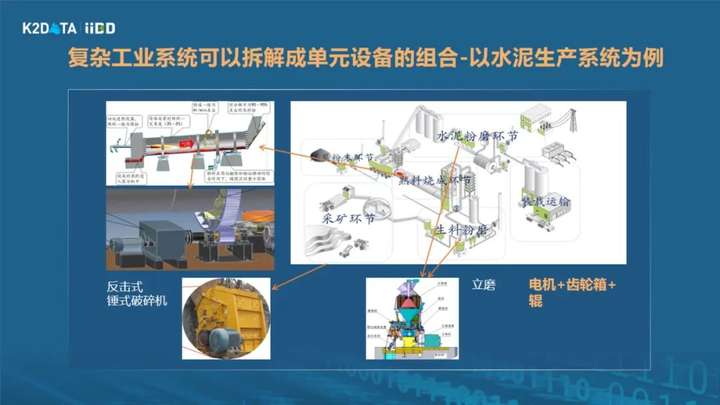
而不同行业中看起来各不相同的工艺生产系统,拆解开之后其实都会有一些通用设备,当然还会有一些行业专用设备。比如风力发电机,拆开之后有电机、轴承这样的通用部件,还有像叶片、塔筒、机箱盖等专业部件。比如煤矿综采系统,把采煤机、刮板运输机等拆开来看,也有电机、像齿轮箱等通用组件,还有行业专用部件。
工业生产系统都是人工设计的物理系统,物理系统总是满足机械论、还原论,我们可以这种方法把大的复杂系统拆开之后,先研究它的组成部件,再组合起来去理解大系统的运行。因此,基础是做好每一个单体系统的参数化。
以电机这个常见单体设备的参数化为例:要研究一个电机,从电机专业的角度就知道需要看运行参数,包括电流电压等电气参数,以及转速、转距等机械参数,另外还有一些跟运行无关,但是对表征设备健康非常重要的参数,比如振动、温度,温升过高或者是振动过速一定是电机出现了异常。这些都是电机专业领域已经建立起来的专业知识,利用它们可以帮助我们更顺利地建立电机参数化模型,继而做相应的运行分析和健康分析。
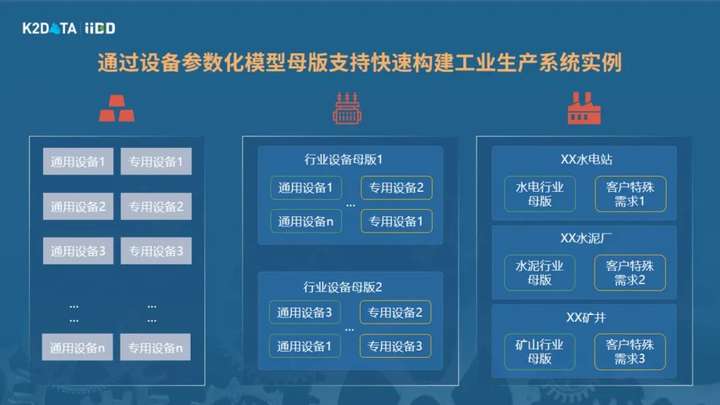
依此延伸一下,要解一个复杂系统的问题,可以通过设备参数化模板的方式,形成通用设备模板和行业设备模板,方便快速设备建模。具体到一个企业,比如一个风电厂,就是由若干风力发电机再加上一些辅助设备如测风塔、升压站等组成,这些组合在一起就成为一个风电行业的通用行业模板,为该行业奠定了很好的数字化建模的基础。
昆仑数据已经把这件事情做成产品,内置了电机等通用设备模型模板,以及一些风电场、水泥厂等行业模板。所以在我们进到一个具体行业的时候,我们不是提供一套通用的技术建模工具,而是有类似设备行业的模板可以复用,而这些模板的建立其实带着大量对于这个领域的专业认知。
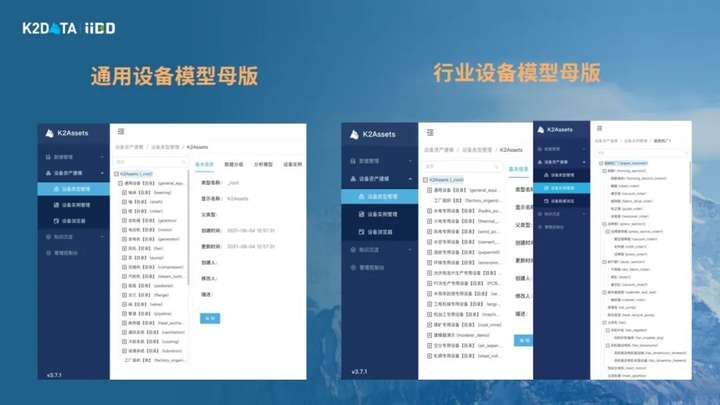
专家知识沉淀--用数据从定性到定量
另外一个挑战是怎么解决专家知识沉淀难的问题。在工业现场,我们不仅要靠工业理论模型,也要靠现场专家知识。专家知识的沉淀以前传统做法是什么呢?靠访谈,让知识工程师去访谈专家,访谈完之后把他的经验记录下来,形成知识库。最早的知识库以文本的方式描述知识,再往后发展到使用知识图谱,但本质上知识图谱也是一种文本,只是更加结构化的表达,其中还是用关联规则来表达,表达能力相对来说就会比较受限,一些很复杂的知识,没有办法做精确表达。那有什么办法能够比现在知识图谱做得更好一点呢?经过这些年的一些实践,我们发现还是有机会的。
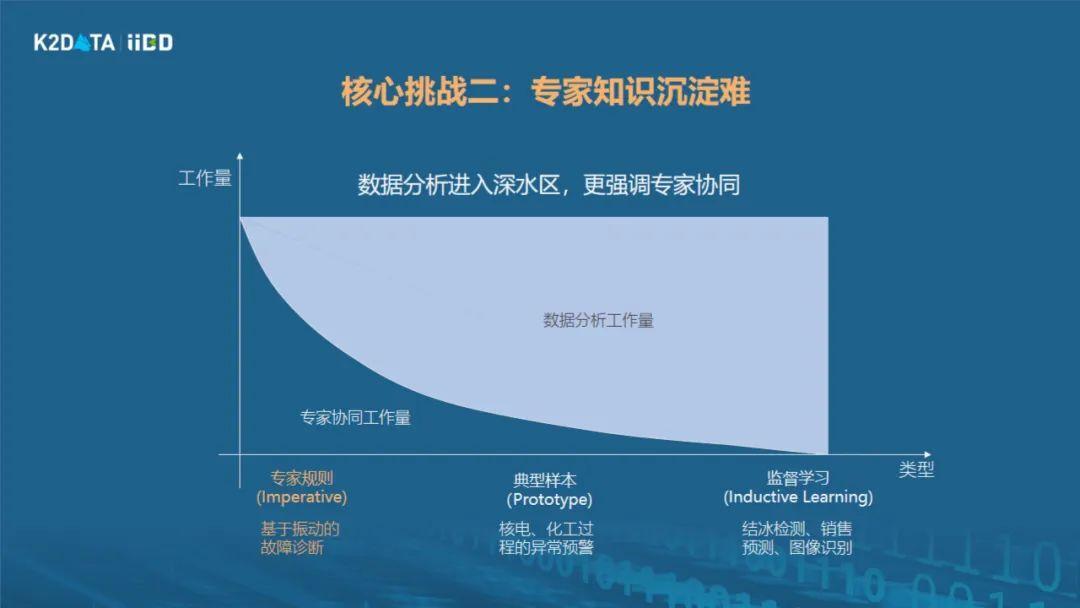
在工业分析,尤其是跟工业的物理系统、生产系统相关的分析领域里面,有非常多的共性场景,这些共性场景在工业现场专家看来,有一些所谓的“套路”。比如说要做故障诊断,就跟人看病相似,比如说要看心脏是否异常,心电图就是原始数据,先看原始数据有没有什么特征,再结合工作生活习惯等等,综合研判是否患病。
做设备故障诊断和人看病过程非常像,只是更复杂。比如风力发电机有500个测点,就类似有500条心电图,要在500个心电图中找关联特征,结合医生的研判规则,最后能出结论。而如何将专家经验、规则和数据深度结合,短时间内在五百个心电图中找出关联关系,并能够判断出这是何种特征,靠人力计算是不现实的,一定是要靠计算机,靠大数据算法来挖掘相关性。通过这样的方式把专家经验变成一个可以用数据精确描述的算法,变成一个软件,到平台上运行。当然工业知识的沉淀有一个逐步完善的过程,我们已经做了一些工作,但还是远远不够,所以我们也提供了一套低代码开发的环境,支持工业现场的工程师可以自主持续地去发现和沉淀更多经验,形成更多行业分析模板,推动生产过程的数智化进程。
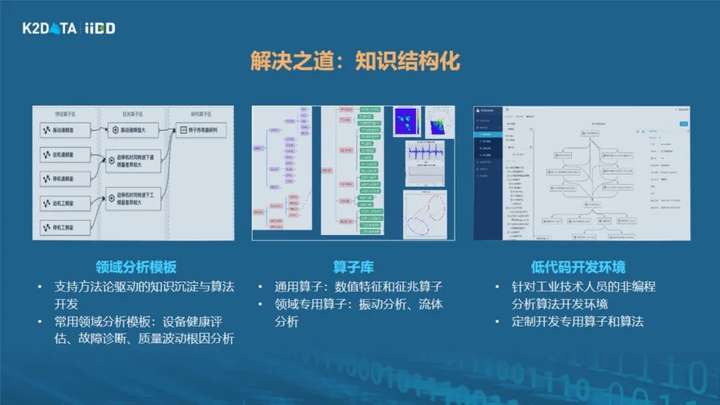
过去我们已经把这样一套领域知识驱动工业数智化的方法和产品,应用到了新能源、工程机械、半导体、高端电子制造等不同行业的龙头企业,帮助他们做核心产品和业务的数字化转型,证实是行之有效的,甚至我们能够做到授人以渔,把这样方法教给企业,让企业内部有效自主开发解决自身的问题。由于时间关系,案例不能展开,下次有机会再跟大家分享。
专家简介
陆薇博士,昆仑数据创始人&CEO,北京工业大数据创新中心主任。曾任IBM物联网重大研发专项(Big Bet)全球技术负责人,兼任清华大学工业大数据中心副主任,《中国制造2025》路线图编写组成员,中关村高聚人才。近年来,推动工业大数据及人工智能技术在中国工业领域的创新与应用,在能源电力、半导体、显示面板、电子制造、工程机械、钢铁冶金等领域有业界领先的探索实践。
服务
Copyright@2025昆仑智汇数据科技(苏州)有限公司 版权所有
北京市海淀区中关村东路8号东升大厦B座805AB
