专家知识沉淀--用数据从定性到定量
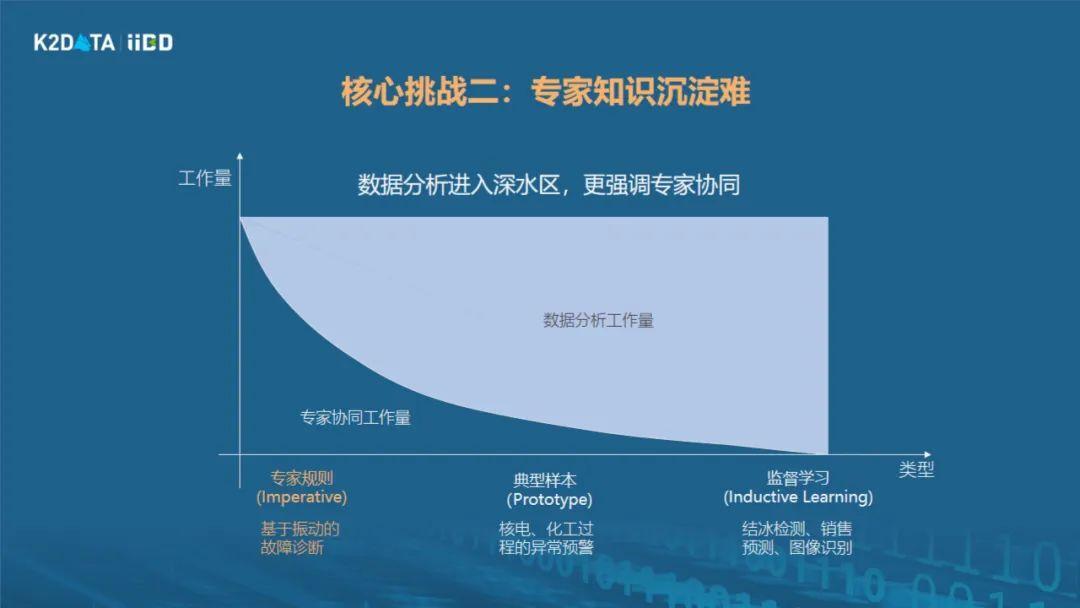
另外一个挑战是怎么解决专家知识沉淀难的问题。在工业现场,我们不仅要靠工业理论模型,也要靠现场专家知识。专家知识的沉淀以前传统做法是什么呢?靠访谈,让知识工程师去访谈专家,访谈完之后把他的经验记录下来,形成知识库。最早的知识库以文本的方式描述知识,再往后发展到使用知识图谱,但本质上知识图谱也是一种文本,只是更加结构化的表达,其中还是用关联规则来表达,表达能力相对来说就会比较受限,一些很复杂的知识,没有办法做精确表达。那有什么办法能够比现在知识图谱做得更好一点呢?经过这些年的一些实践,我们发现还是有机会的。
在工业分析,尤其是跟工业的物理系统、生产系统相关的分析领域里面,有非常多的共性场景,这些共性场景在工业现场专家看来,有一些所谓的“套路”。比如说要做故障诊断,就跟人看病相似,比如说要看心脏是否异常,心电图就是原始数据,先看原始数据有没有什么特征,再结合工作生活习惯等等,综合研判是否患病。
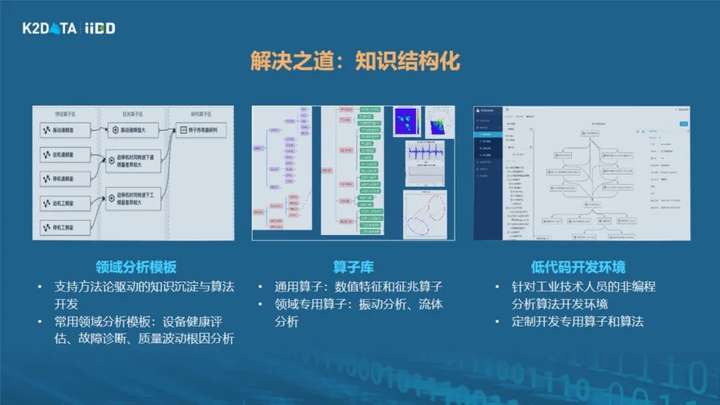
做设备故障诊断和人看病过程非常像,只是更复杂。比如风力发电机有500个测点,就类似有500条心电图,要在500个心电图中找关联特征,结合医生的研判规则,最后能出结论。而如何将专家经验、规则和数据深度结合,短时间内在五百个心电图中找出关联关系,并能够判断出这是何种特征,靠人力计算是不现实的,一定是要靠计算机,靠大数据算法来挖掘相关性。通过这样的方式把专家经验变成一个可以用数据精确描述的算法,变成一个软件,到平台上运行。当然工业知识的沉淀有一个逐步完善的过程,我们已经做了一些工作,但还是远远不够,所以我们也提供了一套低代码开发的环境,支持工业现场的工程师可以自主持续地去发现和沉淀更多经验,形成更多行业分析模板,推动生产过程的数智化进程。
过去我们已经把这样一套领域知识驱动工业数智化的方法和产品,应用到了新能源、工程机械、半导体、高端电子制造等不同行业的龙头企业,帮助他们做核心产品和业务的数字化转型,证实是行之有效的,甚至我们能够做到授人以渔,把这样方法教给企业,让企业内部有效自主开发解决自身的问题。由于时间关系,案例不能展开,下次有机会再跟大家分享。
专家简介
陆薇博士,昆仑数据创始人&CEO,北京工业大数据创新中心主任。曾任IBM物联网重大研发专项(Big Bet)全球技术负责人,兼任清华大学工业大数据中心副主任,《中国制造2025》路线图编写组成员,中关村高聚人才。近年来,推动工业大数据及人工智能技术在中国工业领域的创新与应用,在能源电力、半导体、显示面板、电子制造、工程机械、钢铁冶金等领域有业界领先的探索实践。

