三、数据准备阶段
数据分析通常基于多张数据表的综合分析,有大量数据表连接、聚合的工作,在加上数据质量问题杂多,涉及到大量的边界检查与处理,大模型可以一定程度降低数据准备的工作。
1、数据集的智能整合
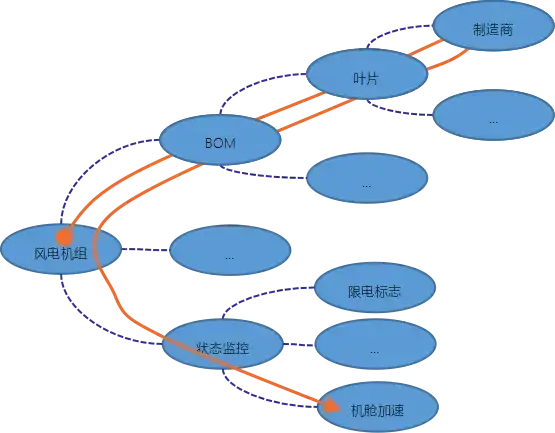
以行业数据模型为基础,大数据平台提供基于图搜索技术的语义查询模型,以友好的方式支撑设备管理分析。以风电机组为例,当叶片发生断裂事故后,整机制造商的运维主管想要查看并确认是否为叶片批次问题(即和当前风机使用同一叶片厂商的风机的近期机舱加速度是否正常),查询路径如图1所示。有了图语义模型的支持,应用开发者无须编写复杂的表间关联语句,将大大降低应用开发的工作量。
图1 风电机组查询示例
查询路径有两个来源,1)用户可以给定查询路径,在如下图所示的领域模型中,用户给出查询路径和初始的查询条件,两个实体间关联关系由领域模型实现,用GraphQL等图查询语言表达,2)大模型自动生成查询路径,并转化为图查询语句。
另外,大模型也可以对生成的数据集进行自动描述。从数据源抽取关键业务语义信息(例如,覆盖多少口井,数据的起止日期,有多少有效数据),并抽取关键的数据质量处理函数描述,交由大模型生成数据集的描述,以方便后续利用时更深入了解该数据集。
流图和说明文档生成
在开发之前通常有数据流图设计。但在开发过程中,数据分析师通常会对数据处理逻辑做更新,造成实际的数据流图与设计图并不完全一致。过去通常在项目验收前要求数据分析师去更新实际的数据流图。
有了大模型之后,有可能结合代码注释,从函数代码提取处理步骤描述,形成一个函数的处理逻辑流程图,撰写算法文档。更宏观一层,从数据库表读写语句中分析每个分析函数的输入和输出的数据表,把多个分析函数的输入、输出和数据表关联起来形成数据流图。
四、模型建立阶段
因为存在大量丰富的机器学习算法库和各种效率工具(例如,AutoML等),模型建立在一般机器学习项目并不是瓶颈,这里不再论述。大模型有可能从类似项目代码中自动生成代码框架,也可以辅助模型试验过程管理(让探索更条理化)。
五、模型评价阶段
针对模型评价,机器学习领域有明确的评价方法、指标和工具,具体项目中通常也有明确的业务角度的评价方法,从而,研发期模型评价阶段对大模型没有特别需求。在部署后的运维阶段,大模型可以对模型的运行性能(计算时间、内存占用量等)、模型指标进行即席解读,降低运维工作量。
六、模型部署阶段
到了“模型部署”阶段,这些信息都明确了,但相对于基于历史数据的批量分析,部署阶段通常采用在线增量分析(流计算、批计算、微批计算),前后执行(以下简称为批次)间存在依赖。