1、在线增量逻辑的修改需求识别
将离线逻辑改成在线逻辑关键在于构建合适的状态量,去有效的表征过去的信息。状态量有3种情况:
1)累积量,例如,大风持续时长,当前的累计量可以作为状态量传给下一次计算。
2)跃变型,通常是类别变量或低频更新的参数,例如磨煤机的负荷状态可以作为状态变量供下次在线迭代计算。抽油机有泵调整时候,会在机采数据表中插入一条记录,在下次更新之前可以一直沿用该参数。
3)事件型(或则Interval变量),例如,修井措施的任务的起止时间,它在选择基准功图、修井效果后评估中是重要的参考量。
在线增量逻辑的修改需求的智能识别有2种途径:
1)根据数据分析程序输出的数据表的说明文档,大模型可以将上面3种情况描述作为提示语,发现潜在需要改写的状态量。
2)针对跃变量和时间型,可以采用基于1.3节数据处理流图的规则检查方式,一般来说这些变量的时间频度比待加工的数据表的要低,例如,合并后的表是每口井的日数据,而输入数据表中的措施、清防蜡等记录是不定期的,通常间隔3个月至上。可以统计实体主键(除时间字段之外其他业务主键)下表的更新频度,更新频度比输出表低的表就是潜在需要修改的表。第两种方法可以结合起来,第一种方法的效果依赖于数据表说明文档的质量,第二种方法受限于数据流图的质量。
2、前端界面与分析模型的关联识别
很多分析模型有对应的应用界面。当应用界面出现异常或疑问后,通常会被问到“该页面或控件的数据来自于哪个分析模型?”。1.3节讨论了如何将分析任务与数据表关联起来,同样的逻辑可以将应用界面与数据表关联起来,基于应用前后端的代码,可以分析数据表-后端Restful API的关系,通过前端与后端API的关系最终将前端界面与数据表关联起来。
七、总结
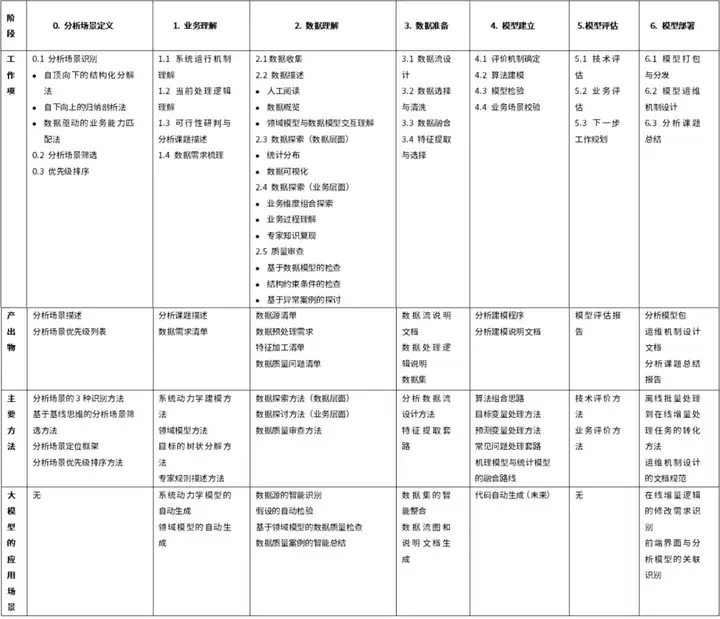
CRISP-DM是一个过程方法,交代清楚了数据分析中的活动(应该做什么),文献给出一些关键活动或任务背后的形式化分析方法,如表1所示。本文讨论各个环节中大模型的潜在应用场景。
表1 敏捷分析的过程模型
从前面的讨论来看,自动化工具目前仍不现实,但大模型(结合规则模型)可以以助手工具的形式提升数据分析效率。根据不同的问题,指导方法作用在不同层面,
1)理念或实指导思想层面的方法,对于复杂事情的思考维度统一认识和做法,例如麦肯锡金字塔原理。
2)过程方法(例如CRISP-DM),将一件复杂的事情分解为步骤,对于关键步骤有具体指导原则,这样让事情执行更条理;
3)内容层面的方法,提供具体的参考内容,让过程变得更有效;